
تخيل نفسك جالسًا مسترخيًا على الأريكة وتطلب فقط من الكمبيوتر أو الكمبيوتر المحمول أو الهاتف الخلوي تنفيذ مهام بسيطة مثل كتابة حرف أو تنفيذ بعض الأوامر. هل هو ممكن؟
بالطبع هذا هو المكان الذي يظهر فيه التعرف على الصوت.
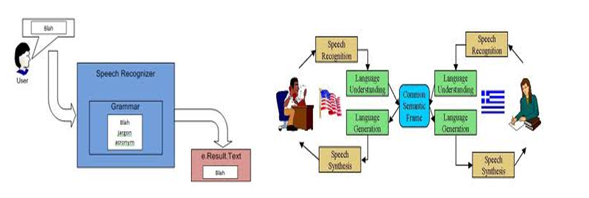
الذهاب من خلال التعريف هو عملية التعرف على الكلام البشري وفك تشفيره إلى شكل نصي.
مبدأ
المبدأ الأساسي لـ التعرف على الصوت يتضمن حقيقة أن الكلام أو الكلمات التي يتحدث بها أي إنسان تسبب اهتزازات في الهواء ، تُعرف باسم الموجات الصوتية. تتم ترقيم هذه الموجات المستمرة أو التناظرية ومعالجتها ثم فك تشفيرها إلى كلمات مناسبة ثم جمل مناسبة.

مكونات نظام التعرف على الكلام
إذن ما الذي يتكون منه نظام التعرف على الكلام الأساسي؟

- جهاز التقاط الكلام : يتكون من ميكروفون يقوم بتحويل إشارات الموجة الصوتية إلى إشارات كهربائية ومحول تناظري إلى رقمي يقوم بأخذ عينات من الإشارات التناظرية وتحويلها رقميًا للحصول على البيانات المنفصلة التي يمكن أن يفهمها الكمبيوتر.
- وحدة إشارة رقمية أو معالج : يقوم بمعالجة إشارة الكلام الأولية مثل تحويل مجال التردد ، واستعادة المعلومات المطلوبة فقط ، إلخ.
- تخزين الإشارات المجهزة مسبقًا : يتم تخزين الكلام المعالج مسبقًا في الذاكرة لتنفيذ مهمة أخرى للتعرف على الكلام.
- أنماط الكلام المرجعية : يتكون الكمبيوتر أو النظام من أنماط كلام محددة مسبقًا أو قوالب مخزنة بالفعل في الذاكرة ، لاستخدامها كمرجع للمطابقة.
- خوارزمية مطابقة الأنماط : تتم مقارنة إشارة الكلام غير المعروفة بنمط الكلام المرجعي لتحديد الكلمات الفعلية أو نمط الكلمات.
عمل النظام
الآن دعونا نرى كيف يعمل النظام بأكمله بالفعل.

- يمكن النظر إلى الكلام على أنه شكل موجة صوتية ، أي إشارة تحمل معلومات الرسالة. يمكن للإنسان العادي مع معدل حركة محدود لمفاصله (أعضاء الكلام) أن ينتج الكلام بمعدل متوسط يبلغ 10 أصوات في الثانية. يبلغ متوسط معدل المعلومات حوالي 50-60 بت / ثانية. هذا يعني في الواقع أن 50 بت / ثانية فقط من المعلومات مطلوبة في إشارة الكلام. يتم تحويل هذا الشكل الموجي الصوتي إلى إشارات كهربائية تناظرية بواسطة الميكروفون. يقوم المحول التناظري إلى الرقمي بتحويل هذه الإشارة التناظرية إلى عينات رقمية عن طريق أخذ قياسات دقيقة للموجة على فترات منفصلة.
- تتكون الإشارة الرقمية من دفق من الإشارات الدورية التي تم أخذ عينات منها بمعدل 16000 مرة في الثانية وهي غير مناسبة لتنفيذها فعليًا التعرف على الكلام عملية حيث لا يمكن تحديد موقع النمط بسهولة. لاستخراج المعلومات الفعلية ، يتم تحويل الإشارة في المجال الزمني إلى إشارة في مجال التردد. يتم ذلك بواسطة معالج الإشارات الرقمية باستخدام تقنية FFT. في الإشارة الرقمية ، المكون بعد كل 1/100ذمن الثانية يتم تحليلها ويتم حساب الطيف الترددي لكل مكون. بمعنى آخر ، يتم تجزئة الإشارة الرقمية إلى أجزاء صغيرة من اتساع التردد.
- يمثل كل جزء أو الرسم البياني للتردد الأصوات المختلفة التي يصدرها البشر. يقوم الكمبيوتر بمطابقة الأجزاء غير المعروفة مع الصوتيات المخزنة للغة معينة. تتم مطابقة النمط هذا بثلاث طرق:
باستخدام النهج الصوتي الصوتي : في النهج الصوتي ، يتم استخدام نموذج ماركوف المخفي بشكل عام. يطور هذا النموذج نموذج احتمالية غير حتمية للتعرف على الكلام. يتكون هذا النموذج من متغيرين - الحالات المخفية للفونيمات المخزنة في ذاكرة الكمبيوتر وقطاع التردد المرئي للإشارة الرقمية. كل صوت له احتمالية خاصة به ويتم مطابقة المقطع مع الصوت وفقًا للاحتمال ثم يتم تجميع الصوتيات المتطابقة معًا لتشكيل الكلمات الصحيحة وفقًا لقواعد اللغة المخزنة.
باستخدام نهج التعرف على الأنماط : في نهج التعرف على الأنماط ، يتم تدريب النظام بنمط كلام معين لأي لغة ويتم مقارنة نمط الكلام غير المعروف بنمط الكلام المرجعي من خلال تحديد المسافة بين الإشارات باستخدام تقنية تزييف الوقت.
استخدام الذكاء الاصطناعي : يعتمد نهج الذكاء الاصطناعي على استخدام مصادر المعرفة الأساسية مثل معرفة الأصوات المنطوقة على أساس القياسات الطيفية ، ومعرفة الكلمات المناسبة ذات المعنى والنحوية.
العوامل التي يعتمد عليها نظام التعرف على الكلام
يعتمد نظام التعرف على الكلام على العوامل التالية:
- كلمات متفرقة : يجب أن يكون هناك توقف مؤقت بين الكلمات المتتالية المنطوقة لأن الكلمات المستمرة يمكن أن تتداخل مما يجعل من الصعب على النظام فهم متى تبدأ الكلمة أو تنتهي. وبالتالي يجب أن يكون هناك صمت بين الكلمات المتتالية.
- مكبر صوت واحد : العديد من المتحدثين الذين يحاولون إعطاء إدخال الكلام في نفس الوقت يمكن أن يسبب تداخلًا في الإشارات وانقطاعات. معظم أنظمة التعرف على الكلام المستخدمة هي أنظمة تعتمد على مكبر الصوت.
- حجم المفردات : يصعب النظر في اللغات ذات المفردات الكبيرة لمطابقة الأنماط من تلك التي تحتوي على مفردات صغيرة حيث تقل فرص وجود كلمات غامضة في الثانية.
نظام التعرف على الكلام في Windows 7
أود أن أوصي بالخطوات التالية لأي شخص يستخدم Windows 7 لنظام التعرف على الكلام
- افتح لوحة التحكم من قائمة البداية أو بالضغط على الأيقونة.
- حدد سهولة الوصول ثم انقر فوق التعرف على الكلام.
- بعد ذلك ، انقر فوق إعداد الميكروفون وحدد ميكروفون سطح المكتب من الخيارات المتاحة.
- بعد ذلك ، خذ دروس الكلام واتبع التعليمات المقدمة.
- بعد ذلك ، قم بتدريب جهاز الكمبيوتر الخاص بك للحصول على خيارات أفضل حتى يخزن الكمبيوتر نمطًا محددًا لإشارة كلامك. يتم ذلك بالنقر فوق الخيار 'تدريب جهاز الكمبيوتر الخاص بك لفهمك بشكل أفضل' ثم اتباع التعليمات.
- ابدأ الآن رمز التعرف على الكلام وابدأ في إملاء كلامك على الكمبيوتر. يمكنك أيضًا إضافة كلماتك الخاصة إلى قاموس الكمبيوتر.
أنظمة التعرف على الكلام العملية: باستخدام HM2007
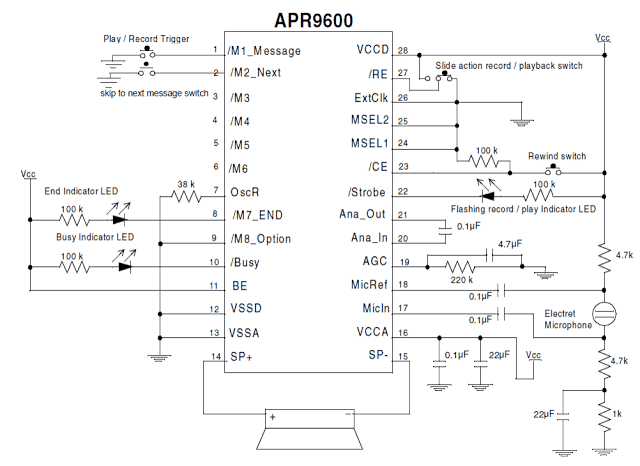
يمكن إنشاء نظام عملي للتعرف على الكلام باستخدام Speech Recognition IC HM2007 . HM2007 عبارة عن 48 دبوس IC الذي يوفر وظيفة التعرف على الكلام. يعمل في وضعين: الوضع اليدوي أو وضع وحدة المعالجة المركزية. في كلا الوضعين ، يتم تدريب IC أولاً على التعرف على الكلمات من قبل المستخدم الذي يقول كل كلمة لرقم مطابق يتم الضغط عليه على المفتاح. يقوم IC بتخزين كل إشارة كلمة في موقع الذاكرة المقابل للكلمة. يتم توصيل إخراج البيانات من IC إلى وحدة التحكم الدقيقة من حيث يتم عرضها على شاشة LCD.

عادة نستخدم الوضع اليدوي لتشغيل HM2007.
- يتكون HM2007 من دبوس RDY وهو دبوس منخفض نشط يشير إلى أن IC جاهز لغرض التدريب.
- سيتم إدخال إدخال الصوت من خلال ميكروفون متصل بدبوس MICIN الخاص بـ IC.
- يتم توصيل IC بلوحة مفاتيح تُستخدم لتوفير إدخال رقم مطابق لكل كلمة. يعمل IC في وظيفتين - مسح وتدريب. عند الضغط على مفتاح القطار على لوحة المفاتيح ، يبدأ IC في عملية التدريب.
- يضغط المستخدم على مفتاح رقم قبل الضغط على مفتاح الوظيفة 'تدريب' ويقول الكلمة المطلوبة للميكروفون.
- يرسل IC إشارة عالية إلى دبوس ME (تمكين الذاكرة) المتصل بدبوس ME المقابل في SRAM. يتم تخزين إشارة البيانات ذات 8 بت المقابلة للرقم الذي تم الضغط عليه في ذاكرة الوصول العشوائي SRAM (ذاكرة الوصول العشوائي الخارجية) عبر الناقل الخارجي.
- بعد اكتشاف الإدخال الصوتي ، يكون RDY pin في مستوى المنطق العالي ويأتي IC إلى حالة التعرف ، حيث يبدأ عملية التعرف.
- يتم إعطاء نتيجة العملية من خلال ناقل البيانات مع ارتفاع دبوس DEN (تمكين البيانات).
- يمكن بعد ذلك إعطاء بيانات 8 بت إلى وحدة التحكم الدقيقة من خلال معالج واجهة متسلسل أو يتم غلقها أولاً باستخدام قفل IC 74HC573.
- يتم توصيل المتحكم الدقيق بشاشة LCD ويتم برمجته بحيث يتم عرض الكلمة المقابلة على الشاشة.
الاحتياط الوحيد الذي يجب اتخاذه هو عدم استخدام متجانسات (كلمات ذات صوت مشابه) وكذلك الاهتمام بالإثارة في الصوت.
إذن ، هذا هو كل شيء كيف أ نظام التعرف الأساسي على الكلام يعمل. أي مدخلات أخرى موضع ترحيب ليتم إضافتها.
رصيد الصورة
مكونات نظام التعرف على الكلام من خلال مقدمة للتعرف على الكلام ومكبر الصوت - ريتشارد دي بيكوك وداريل إتش جراف







{kind=link}